
Just had a play around connecting Claude AI desktop app to my local dev database using MCP.
Woah!
The way it actively pokes around to determine how to find the answer to a question is amazing to watch.
It makes logical decisions based on what it’s seeing in the db, results from attempted queries, and just basically works it out. This db doesn’t have the most logical structure, but no wrong answers so far.
This deserves more exploration. #ai #claudeai #aideveloper
Recent searches
Search options

#claudeai
0 posts0 participants0 posts today

Anthropic Unveils Interpretability Framework To Make Claude’s AI Reasoning More Transparent
#AI #Anthropic #ClaudeAI #AIInterpretability #ResponsibleAI #AITransparency #MachineLearning #AIResearch #AIAlignment #AIEthics #ReinforcementLearning #AISafety
Anthropic has secured an early legal victory as a judge rejects Universal Music’s effort to stop AI training on song lyrics
#AI #CopyrightLaw #Anthropic #ClaudeAI #UniversalMusic #GenAI #FairUse #AIRegulation #MusicIndustry #AIvsCopyright


 AI
AI  Anthropic's Claude Gets Real-Time Web Search
Anthropic's Claude Gets Real-Time Web Search
 New web search feature boosts Claude’s capabilities with live data access. Supports citations to ensure information accuracy. Targets business users with improved research capabilities. Anthropic plans voice interaction and further expansion soon.
New web search feature boosts Claude’s capabilities with live data access. Supports citations to ensure information accuracy. Targets business users with improved research capabilities. Anthropic plans voice interaction and further expansion soon.

Claude AI di Anthropic supporta la ricerca web come ChatGPT
#AI #Anthropic #ChatBot #ChatGPT #Claude #Claude37Sonnet #ClaudeAI #IntelligenzaArtificiale #MotoreDiRicerca #Notizie #Novità #OpenAI #StatiUniti #TechNews #Tecnologia #USA #WebSearch
https://www.ceotech.it/claude-ai-di-anthropic-supporta-la-ricerca-web-come-chatgpt/

Anthropic Expands Claude with Web Search, Challenging AI-Powered Search Rivals
#AI #GenAI #AISearch #ClaudeAI #Anthropic #AIAssistant #WebSearch #SearchEngines

I asked #ClaudeAI to create a #pyside app that tells the current time in #SwatchInternetTime . It did, and it worked without any issues at all the first time, and did pretty much exactly what I wanted it to do.
I need to look at he code and see if it feels #Python -y,


### Современные текстовые нейросети: от теории к практике
Начало 2025 года ознаменовалось динамичным развитием технологий искусственного интеллекта, где ключевую роль играют крупные языковые модели. Китайская компания DeepSeek бросила вызов лидерам рынка, представив бесплатный чат-бот с открытым исходным кодом, что спровоцировало снижение акций NVIDIA на 10% и заставило Кремниевую долину пересмотреть свои стратегии[1]. Этот прорыв демонстрирует, как новые подходы к обучению моделей и оптимизации вычислительных ресурсов трансформируют индустрию ИИ.
## Основные понятия: нейросети и токенизация
Искусственные нейронные сети имитируют работу человеческого мозга, используя многослойные структуры взаимосвязанных "нейронов" для обработки информации. В контексте языковых моделей это проявляется в способности анализировать и генерировать текст, выявляя сложные закономерности в данных[1].
**Токенизация** представляет собой процесс разбиения текста на смысловые единицы. Например, предложение "ИИ меняет мир" распадается на три токена: ["ИИ", "меняет", "мир"]. Современные языковые модели оперируют контекстными окнами от 4 тыс. до 1 млн токенов, что определяет их способность "запоминать" предыдущие взаимодействия[1].
## Ведущие языковые модели
### OpenAI ChatGPT
Пионер в области языковых моделей, представивший GPT-4 и ChatGPT-5, поддерживающие до 128 тыс. токенов контекста. Универсальность позволяет использовать их как для создания художественных текстов, так и для анализа юридических документов[1]. Коммерческое API стоит $0.03 за 1 тыс. токенов ввода и требует строгой модерации контента.
**Автомобильный аналог**: Mercedes-Benz. **Слоган**: "Лучшее или ничего".
**Ссылка**: https://chat.openai.com/
### DeepSeek-V3
Китайская разработка с открытым исходным кодом, потрясшая рынок технологических компаний. Использует инновационные методы обучения, сокращая бюджет разработки до $6 млн по сравнению с многомиллиардными затратами конкурентов[1]. Бесплатный доступ через приложение R1 с контекстным окном 32 тыс. токенов делает её популярной среди исследователей.
**Автомобильный аналог**: Tesla. **Слоган**: "Ускоряя переход к устойчивой энергетике".
**Ссылка**: https://chat.deepseek.com/
### Anthropic Claude 3
Разработка, ориентированная на анализ длинных текстов с рекордным контекстом в 1 млн токенов. Оптимальна для работы с технической документацией, однако стоимость API достигает $0.25 за 1 тыс. выходных токенов. Отличается строгими этическими фильтрами контента[2].
**Автомобильный аналог**: Volvo. **Слоган**: "For life".
**Ссылка**: https://www.anthropic.com/claude
### Qwen2.5
Совместный проект Alibaba и китайских исследовательских институтов. Поддерживает 64 тыс. токенов и ориентирован на мультиязычность, демонстрируя лучшие результаты для азиатских языков[3]. Бесплатная версия доступна через облачный сервис Aliyun.
**Автомобильный аналог**: Toyota. **Слоган**: "Let's Go Places".
**Ссылка**: https://qianwen.aliyun.com/
## Сравнительный анализ моделей
**Глубина анализа**:
- ChatGPT: 9/10 (универсальность)
- DeepSeek: 8.5/10 (исследовательская направленность)
- Claude 3: 9.5/10 (работа с длинными текстами)
- Qwen2.5: 8/10 (мультиязычность)
**Экономическая эффективность**:
- DeepSeek R1: бесплатно (32k токенов)
- ChatGPT Plus: $20/мес (128k токенов)
- Claude Team: $30/мес (1M токенов)
- Qwen2.5: бесплатно через Aliyun (64k токенов)
**Ограничения**:
- Политическая цензура у китайских моделей
- Высокие требования к оборудованию для локального запуска
- Возможные задержки ответа в облачных решениях при высокой нагрузке
## Будущее индустрии
Падение акций NVIDIA на 10% после выхода DeepSeek свидетельствует о переходе фокуса с аппаратных мощностей на алгоритмическую эффективность. По прогнозам Citi, к 2026 году 70% задач обработки естественного языка будут выполняться моделями с открытым исходным кодом[3].
Развитие локальных решений создаёт новый рынок "персонализированных ИИ", где пользователи смогут обучать модели под свои нужды без зависимости от облачных платформ. Это особенно важно для малого бизнеса и независимых исследователей[4].
## Локальные нейросети: установка и настройка
Платформа **Ollama** делает запуск ИИ-моделей доступным для персональных компьютеров. Требования:
- Видеокарта с 8+ ГБ памяти (RTX 2070/4060)
- 16 ГБ оперативной памяти
- Поддержка CUDA (NVIDIA) или ROCm (AMD)
Установка через терминал:
```bash
curl -fsSL https://ollama.ai/install.sh | sh
ollama run llama3
```
Этот код запускает модель LLaMA 3 с контекстом 8 тыс. токенов. Пользователи отмечают удобную интеграцию с Python-библиотеками для создания кастомных решений, хотя возможны трудности с мультиязычными ответами[6].
**Автомобильный аналог**: Jeep. **Слоган**: "Go Anywhere, Do Anything".
**Ссылка**: https://ollama.ai/
## Заключение
Выбор языковой модели зависит от конкретных задач: DeepSeek предлагает лучшую стоимость для академических исследований, ChatGPT остаётся лидером в универсальности, Claude 3 выделяется обработкой длинных текстов, а Qwen2.5 выигрывает в мультиязычности[5]. С развитием технологий токенизация и оптимизация вычислений продолжат играть ключевую роль в удешевлении и ускорении обработки данных.
### Хэштеги:
#AI #MachineLearning #NeuralNetworks #DeepLearning #NLP #LLM #ChatGPT #ClaudeAI #DeepSeek #Qwen #Ollama #Tokenization #OpenSourceAI #TechTrends #AIResearch #AIModels #AIInnovation
### Литература:
1. Bengio Y., Goodfellow I., Courville A. *Deep Learning*. MIT Press, 2016.
2. Vaswani A. et al. *Attention is All You Need*. NeurIPS, 2017.
3. Brown T. et al. *Language Models are Few-Shot Learners*. NeurIPS, 2020.
4. OpenAI Research. *Scaling Laws for Neural Language Models*, 2020.
5. Hestness J. et al. *Deep Learning Scaling is Predictable, Empirically*. arXiv:1712.00409, 2017.
6. Radford A. et al. *Improving Language Understanding by Generative Pre-Training*. OpenAI, 2018.
7. DeepSeek AI. *Technical Report on DeepSeek-V3*, 2025.
8. Anthropic AI. *Claude Model Architecture and Capabilities*, 2024.
9. Alibaba Cloud Research. *Qwen Model Overview*, 2024.
10. NVIDIA AI Labs. *Future of AI Hardware and Optimization*, 2024.
11. Citigroup AI Analysis. *Market Trends in LLM Development*, 2025.
12. Stanford NLP Group. *Comprehensive Guide to Tokenization*, 2023.
Anthropic оновила свою платформу для розробників, додавши до неї нові функції командної співпраці, зокрема розширивши можливості міркувань для свого асистента Claude AI, долаючи ключові виклики у впровадженні штучного інтелекту на підприємствах.


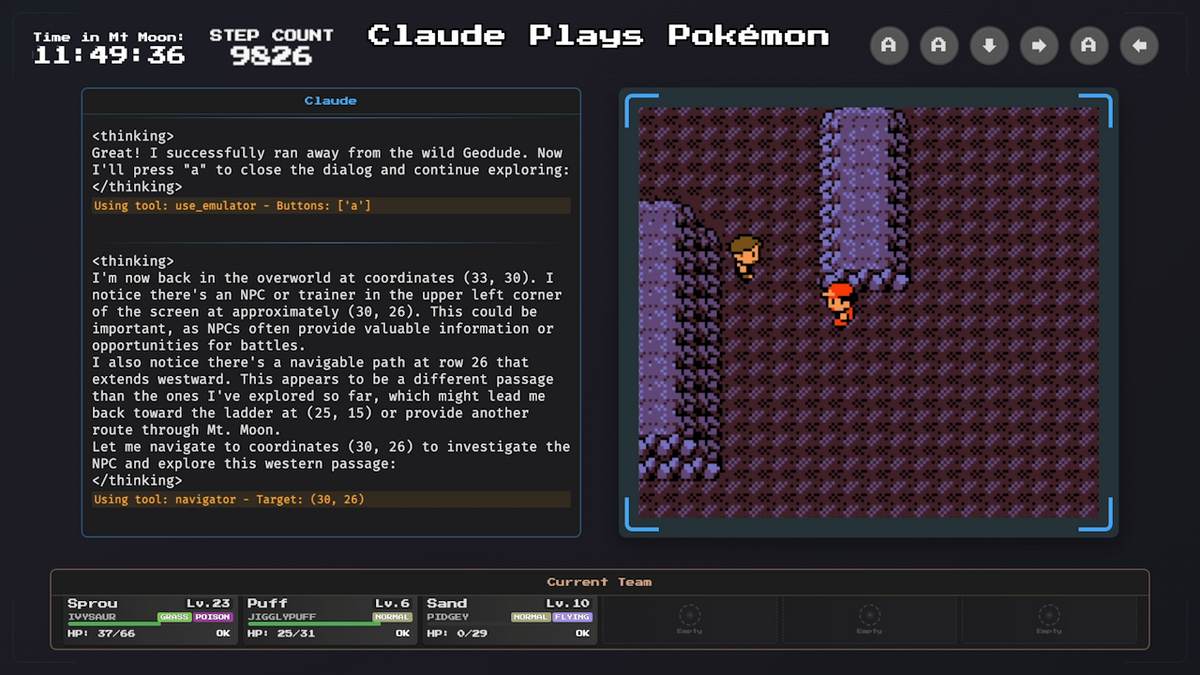
Künstliche Intelligenz Claude spielt Pokémon Rot auf Twitch
Ein Live-Experiment zeigt, wie eine KI durch Reasoning ein Pokémon-Spiel zu bewältigen versucht.
Zur News: https://news.bisafans.de/11424
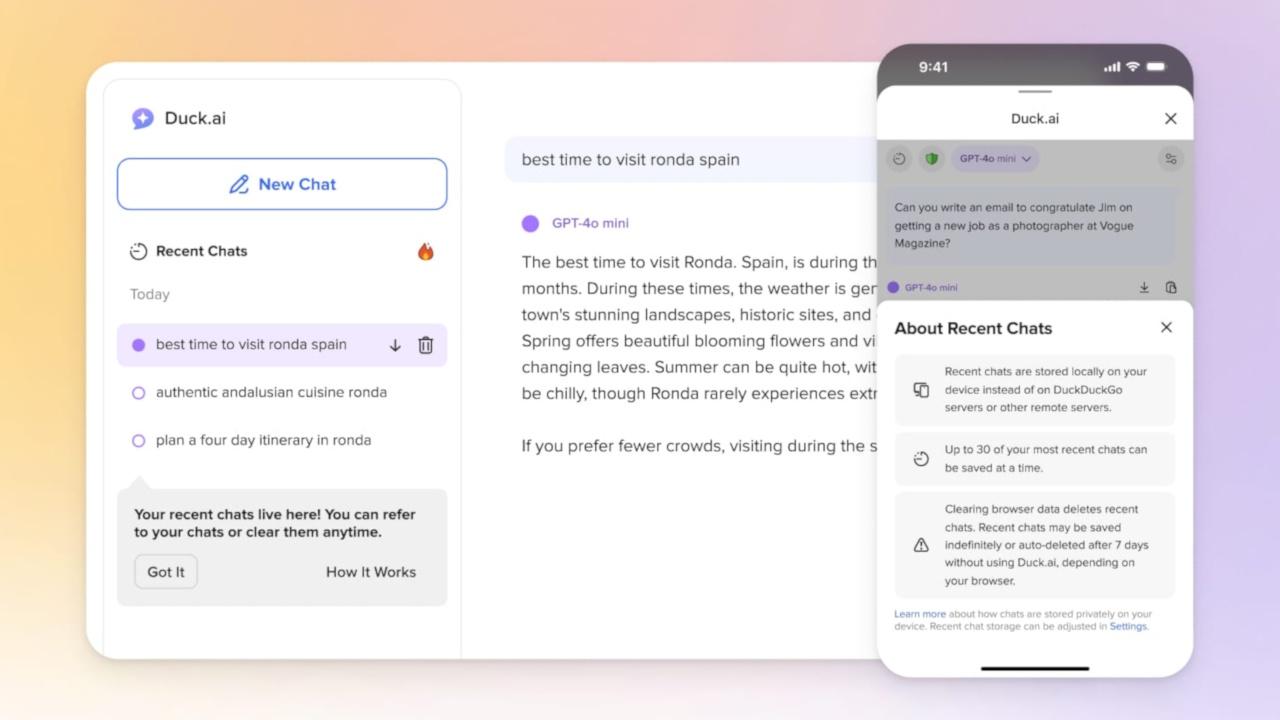
DuckDuckGo Launches AI Search and Chatbot While Keeping Privacy Intact
#AI #DuckDuckGo #AIsearch #PrivacyFirst #chatbots #DataPrivacy #ChatGPT #ClaudeAI ##PrivacyAware #Privacy #Web @duckduckgo
Replied in thread

@carnage4life I don't know what motivated him to say this. 
None of the coding is at this level, decades off being used on critical apps.
It NEVER works 1st time, takes LONGER to fix, writes side-hobby level code, frequently hits valleys it cannot get out of, often ignores what you tell it, and has very limited context.
It answers the question it can answer fastest closest to the question you asked, not the question you asked.
Pure, unadulterated bullshit.

Remember that excellent (11-year-old!) comedy sketch "The Expert"? I'm probably not the first to think of this, but I decided to see how an #LLM would handle the (kinda-)impossible challenge.
The answer is: pretty much how you'd expect. Because they're eager to provide an answer, even where an answer doesn't exist, many #AI will give an invalid answer rather than no answer.
#ClaudeAI was an exception, but that doesn't change the moral of the story: you can't trust #GenAI to do something for you that you couldn't do for yourself.
 Much more, plus screenshots and podcast variant: https://danq.me/ai-vs-the-expert/
Much more, plus screenshots and podcast variant: https://danq.me/ai-vs-the-expert/
Dan Q · AI vs The ExpertInspired by an 11-year old comedy sketch, I asked a GenAI to solve an unsolvable programming problem... and (for at least some models) it failed in exactly the way I anticipated: claiming to be able to solve it and delivering code that just... didn't. What does this teach us about AI trustworthiness for problems that might be solvable, but for which the human operator doesn't have sufficient comprehension to verify?

Claude 3.7 Now Available in GitHub Copilot for Visual Studio.
https://buff.ly/43bnXM1
#ai #visualstudio #githubcopilot #claudeai #anthropic #aiassistant
Claude 3.7 Now Available in Gi...
Visual Studio Blog · Claude 3.7 Now Available in GitHub Copilot for Visual Studio - Visual Studio BlogThe world of AI is evolving at a breathtaking pace, and today brings an exciting milestone for developers and tech enthusiasts alike. Anthropic’s newest release, Claude 3.7, is now available directly within GitHub Copilot for Visual Studio 2022 17.13, heralding a new era of seamlessly integrated, advanced AI coding assistance. This new Sonnet model supports […]


Claude 3.7 Now Available in GitHub Copilot for Visual Studio.
Visual Studio Blog · Claude 3.7 Now Available in GitHub Copilot for Visual Studio - Visual Studio BlogThe world of AI is evolving at a breathtaking pace, and today brings an exciting milestone for developers and tech enthusiasts alike. Anthropic’s newest release, Claude 3.7, is now available directly within GitHub Copilot for Visual Studio 2022 17.13, heralding a new era of seamlessly integrated, advanced AI coding assistance. This new Sonnet model supports […]
Anthropic has reportedly secured $3.5 billion in new funding, bringing its valuation to $61.5 billion #AI #GenAI #Anthropic #ClaudeAI #AIInvestments
https://winbuzzer.com/2025/02/25/anthropic-secures-3-5-billion-in-new-funding-round-xcxwbn/

Replied in thread

There is a simple prompt for #AI to establish if it's hallucinating.
At least with #claudeai there is.
Every time I detect it's making shit up, I ask (literally);
"Claude, are you making shit up?" 9 times out of 10, it will own up.
This puts Claude's numbers way ahead of Franks, the office larrikin, who makes shit up all the time and denies it.


Ich habe ja mal gesagt dass #ChatGPT mit #HomeAssistent überfordert ist. Nachdem ich jetzt ne Weile #ClaudeAI verwendet habe (primär für Übersetzungen) habe ich den mal dafür ausprobiert Und der ist auch da deutlich besser*
Auf Anhieb mein Problem gelöst. Schon ziemlich cool. Vor allem für Systeme wo man nicht so "zu Hause" ist (Pun intended) ne echte Hilfe.
(* habe jetzt nicht alle Varianten von OpenAI durchprobiert)



Claude & Gemini come to Visual Studio with GitHub Copilot with Rhea Patel.
https://www.youtube.com/watch?v=FR-xFbnDgGs
#visualstudio #githubcopilot #ai #claudeai #googlegemini #aiassistant
Claude & Gemini come to Visual...
Claude & Gemini come to Visual Studio with GitHub Copilot with Rhea Patel.