Recent searches
Search options

#crawlers


"[..] 65% of our most expensive traffic comes from #bots" · How #crawlers impact the operations of the @wikimediafoundation projects.
 https://diff.wikimedia.org/2025/04/01/how-crawlers-impact-the-operations-of-the-wikimedia-projects/
https://diff.wikimedia.org/2025/04/01/how-crawlers-impact-the-operations-of-the-wikimedia-projects/


@camwilson #AI #Crawlers are not only increasing bandwidth costs for #Wikipedia, but looking for code on which to train are similarly weighing down open software sources.
It's like some giant monster devouring resources and requiring nuclear fusion and all the fresh drinking water to do not very much. Interesting that animal intelligence gets by without consuming all the data in the world and a few worms, insects, or a peanut butter and jelly sandwich.

#Business #Introductions
Meet LLMs.txt · A proposed standard for AI website content crawling https://ilo.im/16318s
_____
#SEO #GEO #AI #Bots #Crawlers #LlmsTxt #RobotsTxt #Development #WebDev #Backend


 ⁂
⁂ Thanks to Fijxu use of Anubis videos still can be watched on inv.nadeko.net. 
I feel like because of the aggressive bot scraping that intensified not long ago will going to make it impossible to continue to use feed readers and the only way to interact with websites will going to be restricted to only be possible from web browsers.
Already opening up videos in mpv from my rss subscribed invidious feeds not working, it was my preferred way to watch videos. Just to clarify I'm aware that rss still works the only thing that doesn't is opening up video links directly with mpv or with any other video player that can do the same. And not only that but I fear at some point reading full articles inside an rss reader will not work forcing me to open article links in a web browser, even if some of feeds can fetch full articles minimizing the need to do so.
I'm not trying to minimize the impact of this scrapers that have on free and open source projects and on web admins who have to deal with this onslaught of bot activity, they are the ones who got it worst.


"#AI" #crawlers are a cancerous disease that must be eradicated, not just fended off.
»The costs are both technical and financial. The Read the Docs project reported that blocking AI crawlers immediately decreased their #traffic by 75 percent, going from 800GB per day to 200GB per day. This change saved the project approximately $1,500 per month in bandwidth costs, according to their blog post "AI crawlers need to be more respectful."«





Who could have guessed that an industry whose entire business model is based on theft would behave like malware attacks on the Internet? 




Cloudflare wrestling AI scrapers, not that I disagree, but how Cloudflare comes to decide who or what can access a website? They have a nearly monopolistic, man-in-the-middle position (like in CDN)
Challenging times
#Development #Announcements
Trapping bad bots in a labyrinth · Cloudflare can now punish bots breaking ‘no crawl’ rules https://ilo.im/162xjb
_____
#AI #GenerativeAI #Crawlers #Bots #Detection #Protection #Security #Website #WebDev #Backend


Using #AI to fight AI.
Cloudflare builds an AI to lead AI scraper bots into a horrible maze of junk content • The Register
https://www.theregister.com/2025/03/21/cloudflare_ai_labyrinth/


Remember to #block #AI #crawlers with this as well https://github.com/ai-robots-txt/ai.robots.txt


Web crawlers are out of control. If anyone has a suggestion on how to block them entirely, not via robots.txt but with e.g., a prompt that only a human can answer, I'd appreciate it.
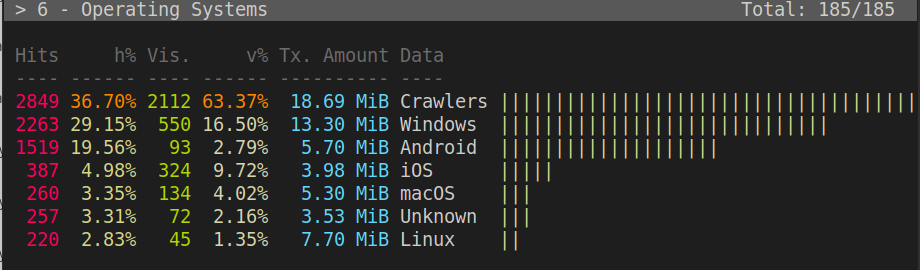
Here, a list of the operating systems of my website's visitors.



The pushback against AI crawlers threatens the transparency & open borders of the web that allow non-AI apps to flourish. If unfixed, the web will increasingly be fortified with logins, paywalls, & access tolls.
#ai #crawlers #transparency #openborders
https://www.technologyreview.com/2025/02/11/1111518/ai-crawler-wars-closed-web/


This is a terrifying read.
2025-01-23 The bots are at it again | https://alexschroeder.ch/view/2025-01-23-bots-devouring-the-web
Sure, my website is "tiny", 100% static, and very fine-tuned (I like to think); but if I had some dynamic content that was mildly popular... oh, dear.

It looks like LLM-producing companies that are massively #crawling the #web require the owners of a website to take action to opt out. Albeit I am not intrinsically against #generativeai and the acquisition of #opendata, reading about hundreds of dollars of rising #cloud costs for hobby projects is quite concerning. How is it accepted that hypergiants skyrocket the costs of tightly budgeted projects through massive spikes in egress traffic and increased processing requirements? Projects that run on a shoestring budget and are operated by volunteers who dedicated hundreds of hours without any reward other than believing in their mission?
I am mostly concerned about the default of opting out. Are the owners of those projects required to take action? Seriously? As an #operator, it would be my responsibility to methodically work myself through the crawling documentation of the hundreds of #LLM #web #crawlers? I am the one responsible for configuring a unique crawling specification in my robots.txt because hypergiants make it immanently hard to have generic #opt-out configurations that tackle LLM projects specifically?
I reject to accept that this is our new norm. A norm in which hypergiants are not only methodically exploiting the work of thousands of individuals for their own benefit and without returning a penny. But also a norm, in which the resource owner is required to prevent these crawlers from skyrocketing one's own operational costs?
We require a new #opt-in. Often, public and open projects are keen to share their data. They just don't like the idea of carrying the unpredictable, multitudinous financial burden of sharing the data without notice from said crawlers. Even #CommonCrawl has safe-fail mechanisms to reduce the burden on website owners. Why are LLM crawlers above the guidelines of good #Internet citizenship?
To counter the most common argument already: Yes, you can deny-by-default in your robots.txt, but that excludes any non-mainstream browser, too.
Some concerning #news articles on the topic:

@iagondiscord The problem is that it's not targeting Codeberg. It's the #AIgoldrush. The web was completely crawled, just not by everyone yet. So startups start their #crawlers, carelessly and explicitly ignoring robots.txt to get the #biggestdata.
It does not matter if the web can no longer serve humanity due to this. Training the #AI is the only thing that matters.
Maybe a bit like a sacrifice for faith.
~f #goldrush
